Paper Reading Notes #01: Attention Is All You Need

This is a new series of my notes on paper reading, covering various areas in computer architecture, algorithms, and machine learning. The first paper is Attention Is All You Need from Google that introduce self-attention mechanism and Transformer to NLP tasks.
The motivation for the Google folks is that RNN models, due to their intrinsic sequential nature, are hard to parallelize on GPUs and accelerator: for RNN to encode information from earlier position in the sequence, it will need to generate a sequence of hidden states in order before the current position can use it. Using attention mechanism, it is possible to collect the information between tokens in a sequence with a few matrix multiplication, making the process much more parallelizable.
Attention and self-attention mechanism
The concept attention is meant to mimic cognitive attention, learning which part of the data is more important than another depending on the context, according to the Wikipedia page. The general idea is as follows:
Let's assume we have a token sequence $t_i$ where each token has a value vector $v_i$. We would like to compute a weighted value vector for a particular token $t_k$ with respect to all the tokens in the sequence. So the output will be $\sum_i{w_{ki}v_i} = 1$ with $\sum_i{w_{ki}} = 1$.
To compute the weight $w_{ki}$, we would use the query-key mechanism and dot-product attention. For this, we defined:
- $q_i$: the query vector related to token $t_i$
- $k_i$: the key vector related to token $t_i$
- $\vec{w_k} = [w_{k1}, ..., w_{kn}]_{1\times n}$
- $K = \begin{bmatrix}
k_1 \\
... \\
k_n
\end{bmatrix} $ - $V = \begin{bmatrix}
v_1 \\
... \\
v_n
\end{bmatrix}_{n\times d_v}$
Now, the weight vector is $\vec{w_k} = softmax(q_kK^T)$ and the final attention vector to be $\vec{w_k}V = \sum_j{w_{kj}v_j}$, being almost what is described in the paper (omitting the scaling part).
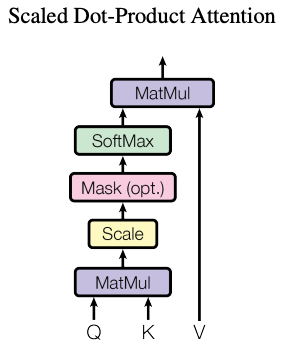
Now for the self-attention part, it basically means that we will be using input sequence to serve both the queries (by stacking the query vector above together), keys, and values matrices. However, if we just use the token embeddings for these matrices, we are not learning anything here. Thus, we will introduce three additional weight matrices $W^Q, W^K, W^V$ and compute the queries, keys, and values matrices as follow:
- $Q = EW^Q$
- $K = EW^K$
- $V = EW^V$
- With:
- $E_{n\times d_{model}}$ is the stacked embedding matrix of the $n$ tokens in the inputs
- $W^Q$ of size $d_{model} \times d_k$
- $W^K$ of size $d_{model} \times d_k$
- $W^V$ of size $d_{model} \times d_V$
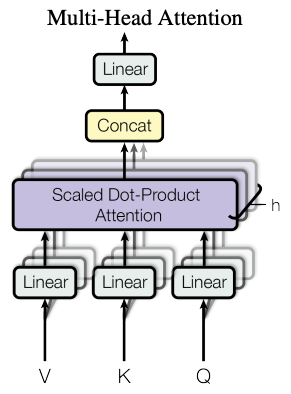
Multi-Head Attention
Another concept the author introduce is Multi-Head Attention, which basically means to replicate the above attention layer for multiple times. Therefore, each sub attention layer is computing a different kind of attention, which I found similar to having multiple kernel filters in CNN network where each filter is learning to detect different feature in the image.