SURF Week 1: GPU Architecture and CUDA Introduction

Since the SURF project I enrolled in involving works related to GPU, the first series of tasks assigned to me were to get familiar with GPU and CUDA programming as I did not have previous experience on these two topics. This article will thus serve as a summary for what I got from reading the introductory materials and should enable people like me to have a basic understanding of GPU and what it does.
What is a GPU?
Generally speaking, GPUs, acronyms for Graphics Processing Unit, can be considered as programmable accelerators that collaborate with CPUs to process certain types of tasks efficiently. Initially the tasks are graphics-related like rendering games scenes and GUIs, with the trends shifted to parallel computation in modern days.
In addition, due to their parallel nature, GPUs have more silicon areas dedicated to computation resources rather than control and cache parts like CPUs. Unlike the serial counterpart CPUs with limited cores count ranging from 2 to 8 most of the time, GPUs usual have tens of thousands processing units on chips to perform massively parallel computations like calculating pixel locations and color combinations.
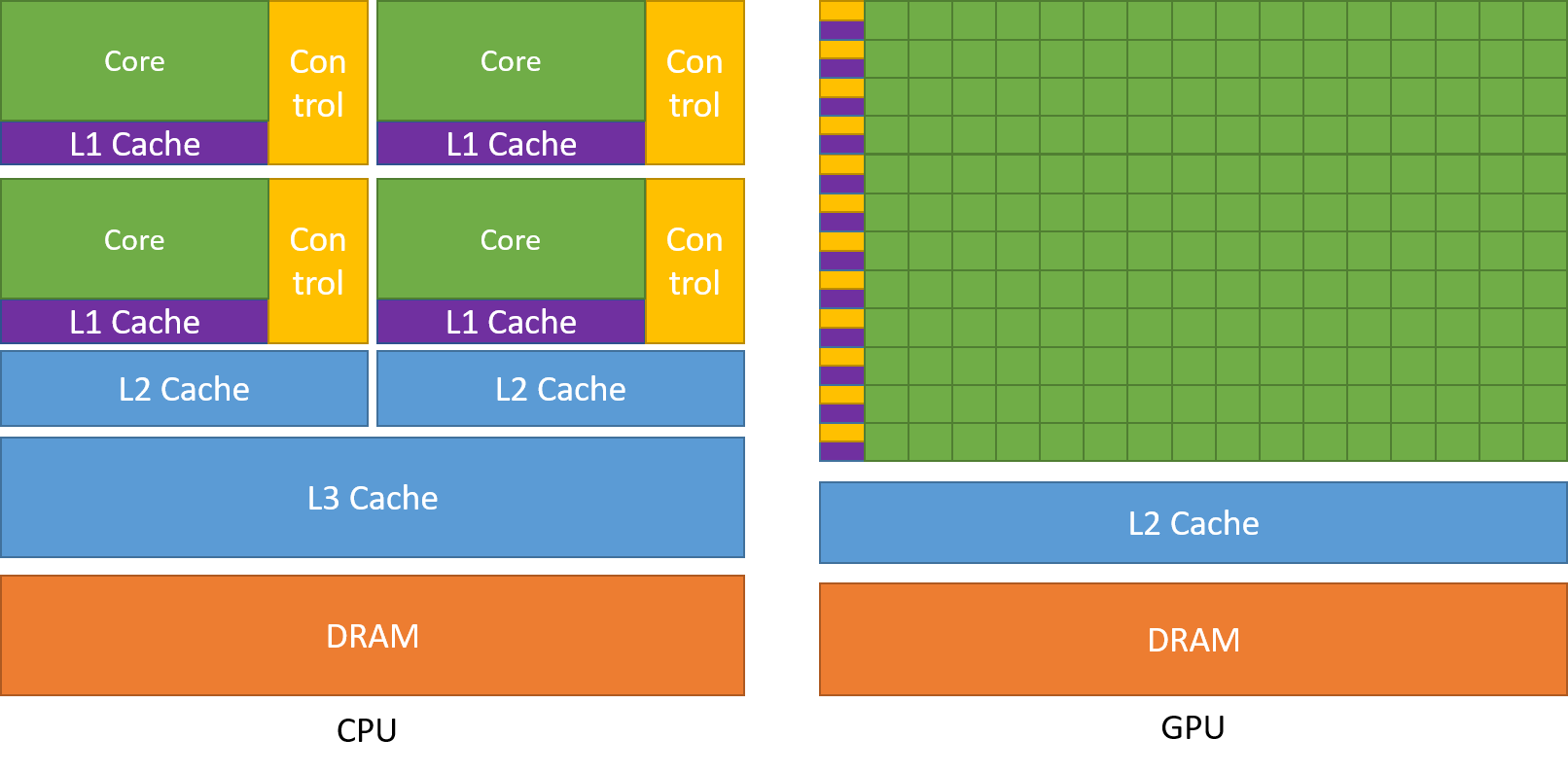
Why can GPUs accelerate tasks?
One thing to note first is that although GPUs are fast, they cannot handle all tasks efficiently. Like mentioned previous, GPUs are especially suitable for parallel computation, which is due to data level parallelism, meaning that we will have identical computation on different data. One example for this is grey-scale conversion for 2D images, where we calculate the illuminance of each pixel via its original RGB values.
Basic CUDA Programming Structure
CUDA is a software toolkit developed by NVIDIA to effectively program its GPUs. The core concept of CUDA is to defined a so called "CUDA Kernel function", which is run on every thread in the CUDA programming model.
In CUDA, to run the Kernel function, we will need to define a Grid with threadblocks, which contains CUDA threads and each thread will run the Kernel function on the actual hardware cores.
To define a kernel function, we have the following template:
__global__ void kernelFunc(float * arg1, ..., float * argn, float * result) {
// Perform the kernel action, like pixel conversion
}
The __global__ keyword tells the nvcc compiler (CUDA compiler) that this function is a kernel function that should be run on a CUDA device. Also noted that all kernel functions must have return type of void.
Then in another function, which known as host code, we called this kernel function:
void hostFunc(float * arg1, ..., float * argn, float * result, int n) {
// Perform memory allocation on the CUDA device
float * arg1_d, * arg2_d, ..., * argn_d, * result_d;
int size = sizeof(float) * n;
cudaMalloc((void **) &arg1_d, size);
...
cudaMalloc((void **) &argn_d, size);
cudaMalloc((void **) &result_d, size);
// Copy the content from host memory to device memory
cudaMemcpy(arg1_d, arg1, size, cudaMemcpyHostToDevice);
...
cudaMemcpy(argn_d, argn, size, cudaMemcpyHostToDevice);
// Call kernel, which will put outputs in result_d as an example
// g_x, ..., b_z are all integers
// Which determined the size of grid and threadblock
dim3 GridDim(g_x, g_y, g_z);
dim3 BlockDim(b_x, b_y, b_z);
kernelFunc<<<GridDim, BlockDim>>>(arg1_d, ..., argn_d, result_d);
// Copy the result from device to host memory
cudaMemcpy(result, result_d, size, cudaMemcpyDeviceToHost);
// Free allocated spaces
cudaFree(arg1_d);
...
cudaFree(result_d);
}
Basically the host code have 5 basic parts:
- Allocate memory space on device memory.
- Copy the input arguments from host memory to device memory.
- Invoke the kernel function with dedicated
GridDimandBlockDim. - Copy the output result from device memory to host memory.
- Clear up allocated memory.
For more information on CUDA programming, one can refer to the NVIDIA CUDA programming guide here.